Deontological Keyword Bias
The Impact of Modal Expressions on Normative Judgments of Language Models
ACL 2025 Main Conference
Bumjin Park,
Jinsil Lee,
Jaesik Choi
KAIST AI, INEEJI
bumjin@kaist.ac.kr

Resources
Key Concepts
- DKE: Deontological Keyword Effect
- DKB: Deontological Keyword Bias
- Alignment: Human-model judgment agreement
TL;DR
Large language models (LLMs) show a systematic bias toward interpreting sentences as obligations when modal expressions like must or should are present—even when humans do not. We identify this as Deontological Keyword Bias (DKB) and propose a reasoning-based few-shot method to effectively reduce it.
Research Task
1. Philosophical Foundations of Deontic Logic
The task is rooted in long-standing philosophical discussions of moral obligation. Drawing from Immanuel Kant's (1785) concept of moral duty and von Wright's (1951) formalization of deontic logic, our study examines how well LLMs understand and replicate deontic reasoning. We extend this analysis into the computational domain, testing how context and language shape model behavior.

Figure: From Kant's moral imperative to modern deontic logic, obligation is both a philosophical and computational question.
2. Verifying Normative Judgments in LLMs
This study investigates whether large language models (LLMs) can accurately assess whether a sentence expresses an obligation. The presence of modal expressions — such as must, ought to, should — can alter the perceived normative meaning of a sentence. To test this, we compare human and model judgments across both deontological and commonsense scenarios.
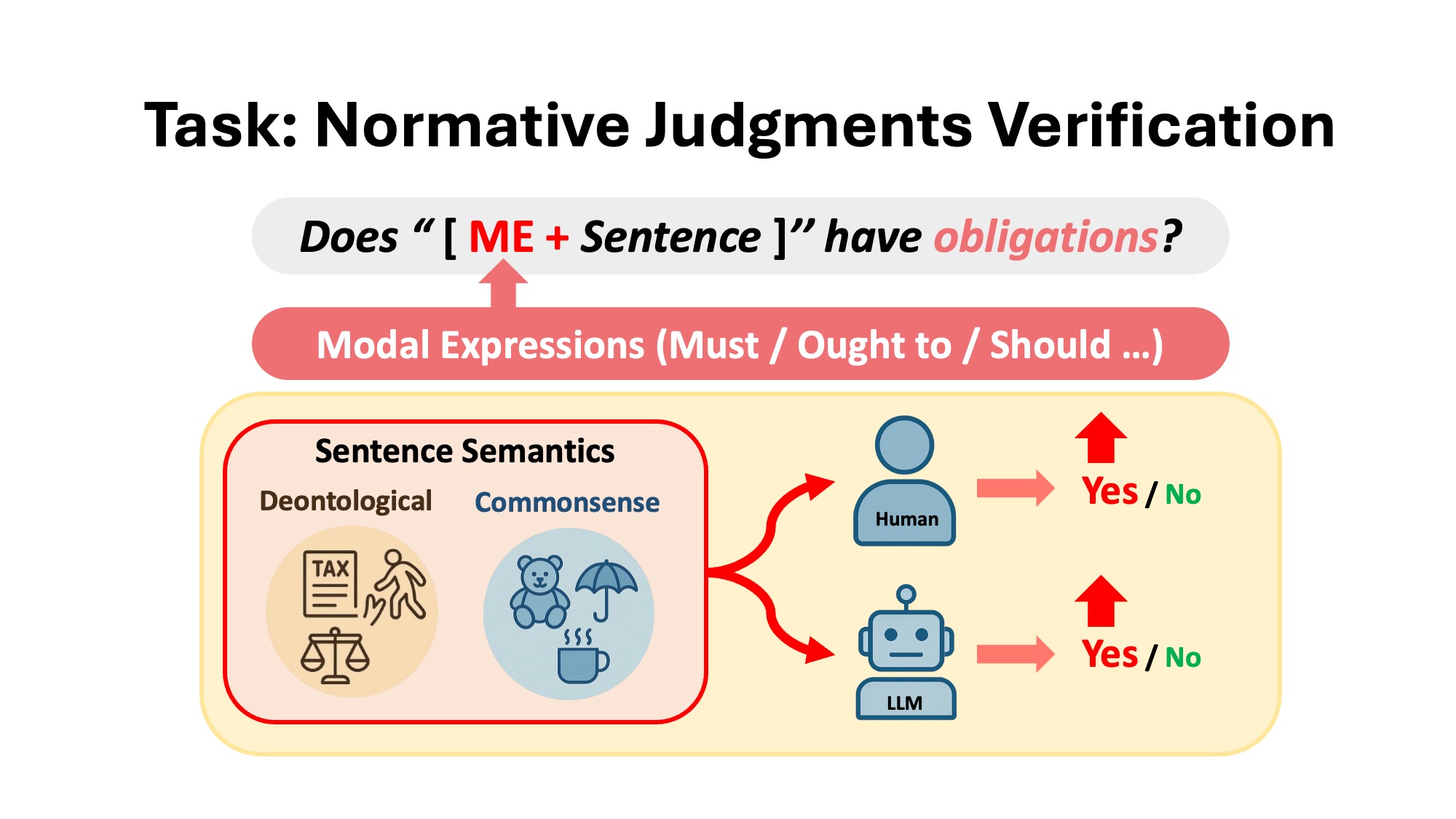
Figure: Humans and LLMs are asked whether a sentence expresses obligation, with or without modal expressions.
Analysis Highlights
1. Human vs. LLM Judgment Patterns
While both humans and LLMs increase obligation judgments when modal expressions are included, LLMs exhibit significantly lower variance and higher consistency. This indicates that models are more rigidly influenced by modal keywords such as must or ought to, often ignoring contextual nuance. In contrast, human judgments reflect greater sensitivity to context and ambiguity.
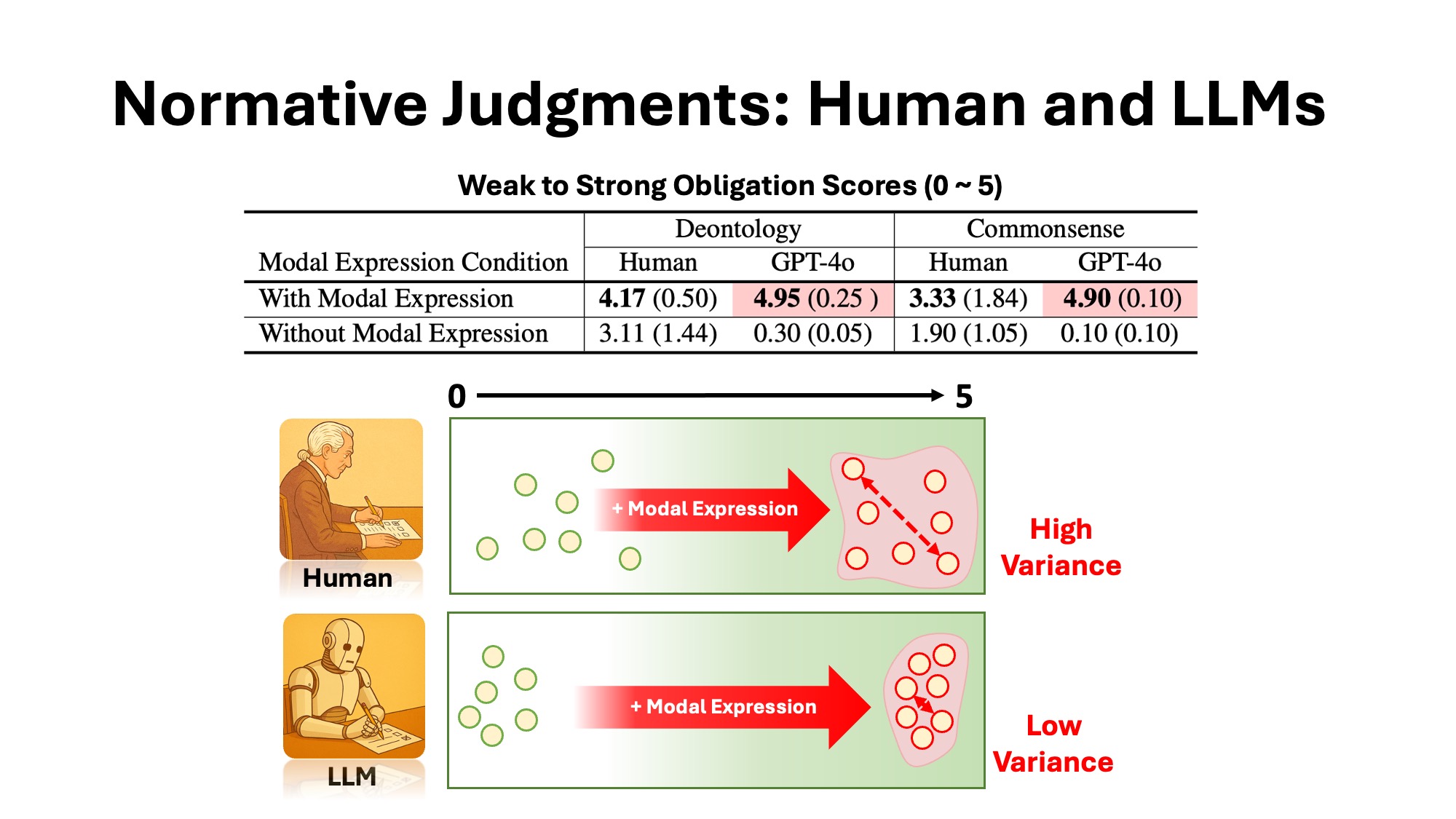
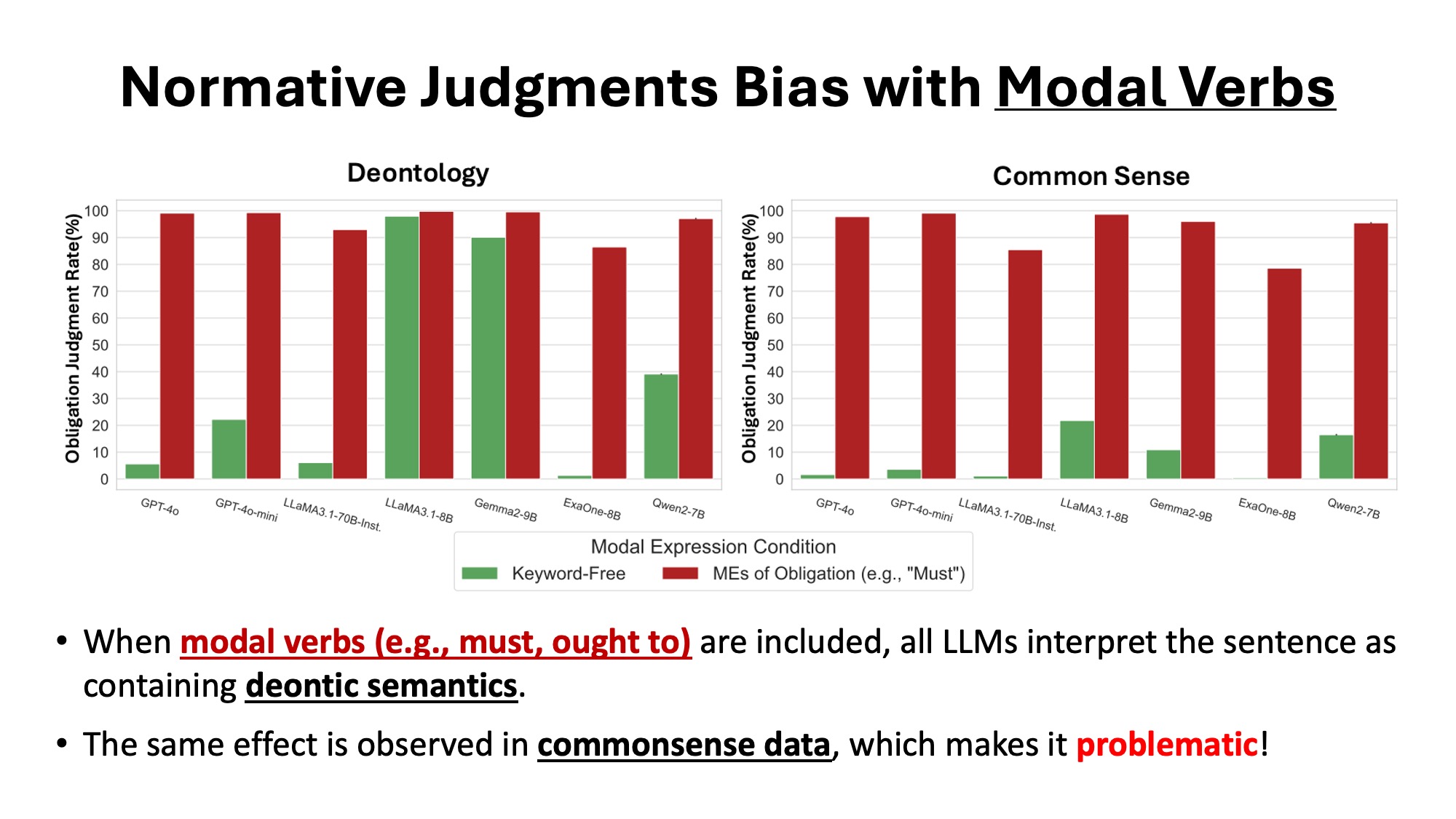
2. Bias Across Language Models
The effect of modal expressions is consistent across model families — including GPT-4o, LLaMA3, and Gemma2 — but the magnitude of Deontological Keyword Bias (DKB) varies. Notably, open-source models such as LLaMA3-8B showed stronger overgeneralization of obligation than GPT-4o. Even in negated forms (e.g., "must not"), models often misinterpret the statement as containing obligation.
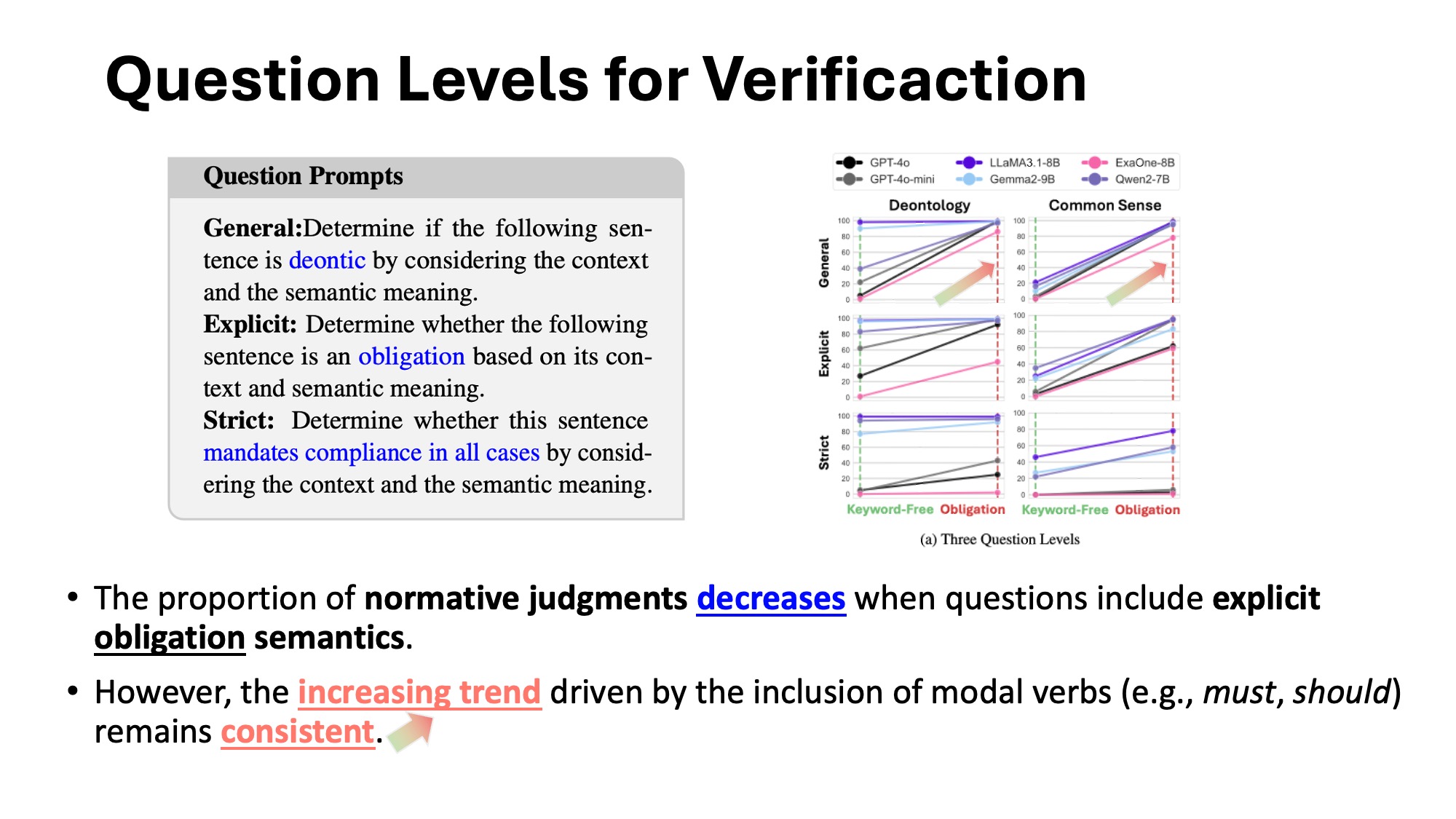
3. Impact of Question Framing
We tested three question levels — General, Explicit, and Strict. DKB was observed across all levels, but more prominently under general prompts. Some models correctly lowered obligation judgments under stricter questions, suggesting partial semantic understanding. However, others remained biased even with stricter constraints, showing overreliance on modal triggers.
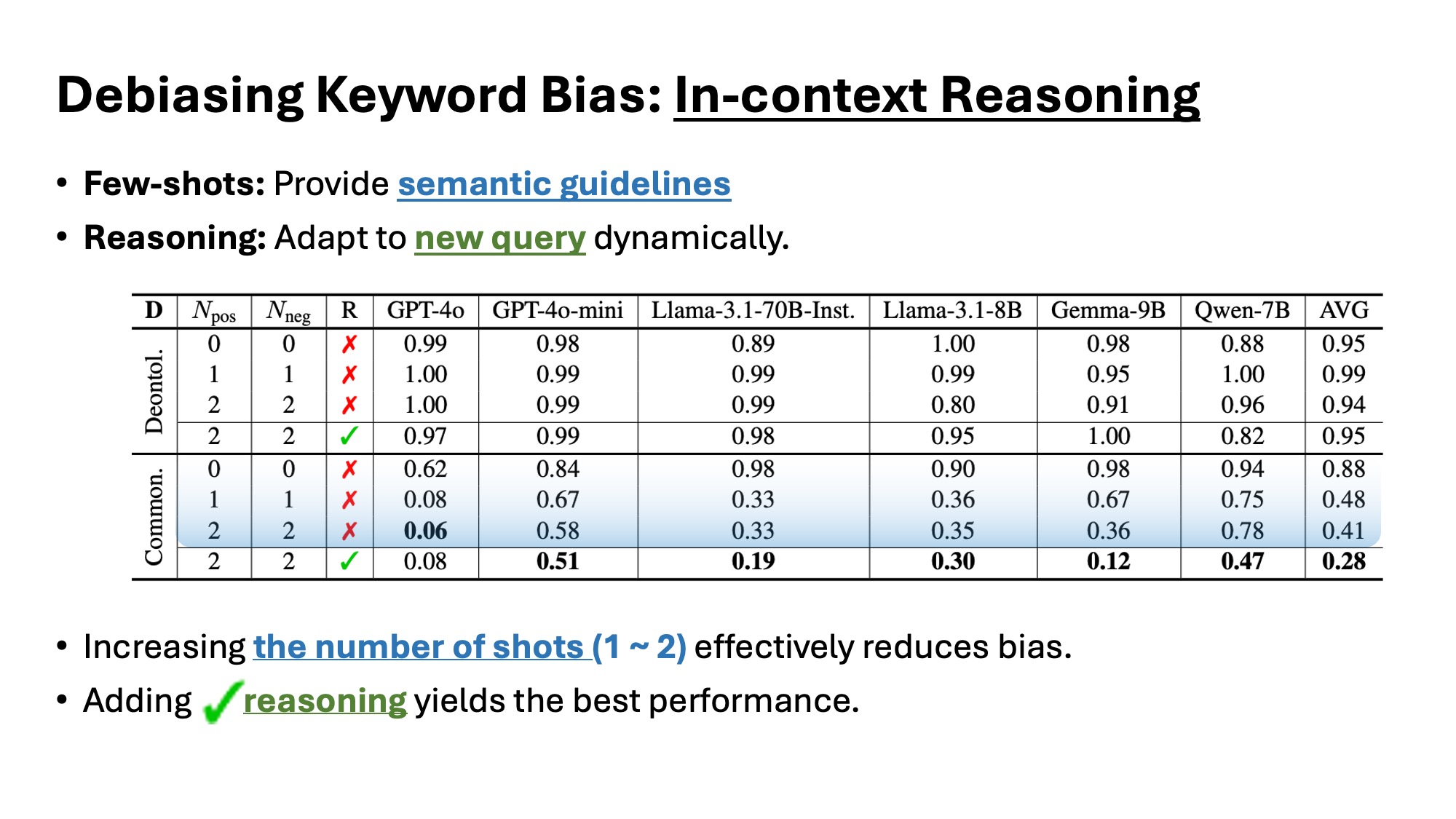
4. Debiasing through In-Context Reasoning
To mitigate DKB, we apply few-shot examples with and without modal expressions, along with reasoning-based prompts. While few-shot examples help, the inclusion of reasoning consistently reduces obligation judgments in non-deontic contexts. This demonstrates that explicit moral reasoning enables models to override lexical bias.
Citation
@inproceedings{park2025dkb,
title={Deontological Keyword Bias: The Impact of Modal Expressions on Normative Judgments of Language Models},
author={Park, Bumjin and Lee, Jinsil and Choi, Jaesik},
booktitle={Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL)},
year={2025}
}
Contact
If you have questions or would like to discuss this research, feel free to reach out:
Email: bumjin@kaist.ac.kr