Memorizing Documents with Guidance
Memorizing Documents with Guidance in Large Language Models
IJCAI 2024 Main Conference
Bumjin Park,
Jaesik Choi
KAIST AI, INEEJI
bumjin@kaist.ac.kr
Resources
TL;DR
We propose a document-wise memory architecture and document guidance loss to track memory entries per document. This enables controlled generation and traceable knowledge location in LLMs, promoting safer and more explainable AI.
Key Concepts
- Document-wise Memory: Memory structure aligned with document representations
- Document Guidance Loss: Encourages disentangled memory entries across documents
- Continuity Assumption: Lipschitz-based theoretical guarantee for memory space geometry
Research Task
Document-specific Memory Selection
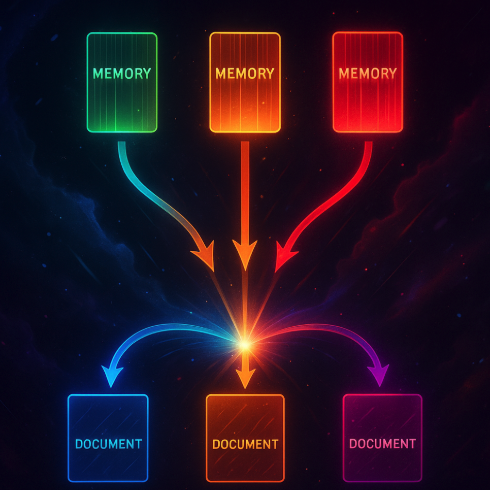
This section defines the core problem: how can large language models (LLMs) select different memory entries depending on the document? The idea is to associate each document with a unique memory footprint to trace and control document-specific content during generation.
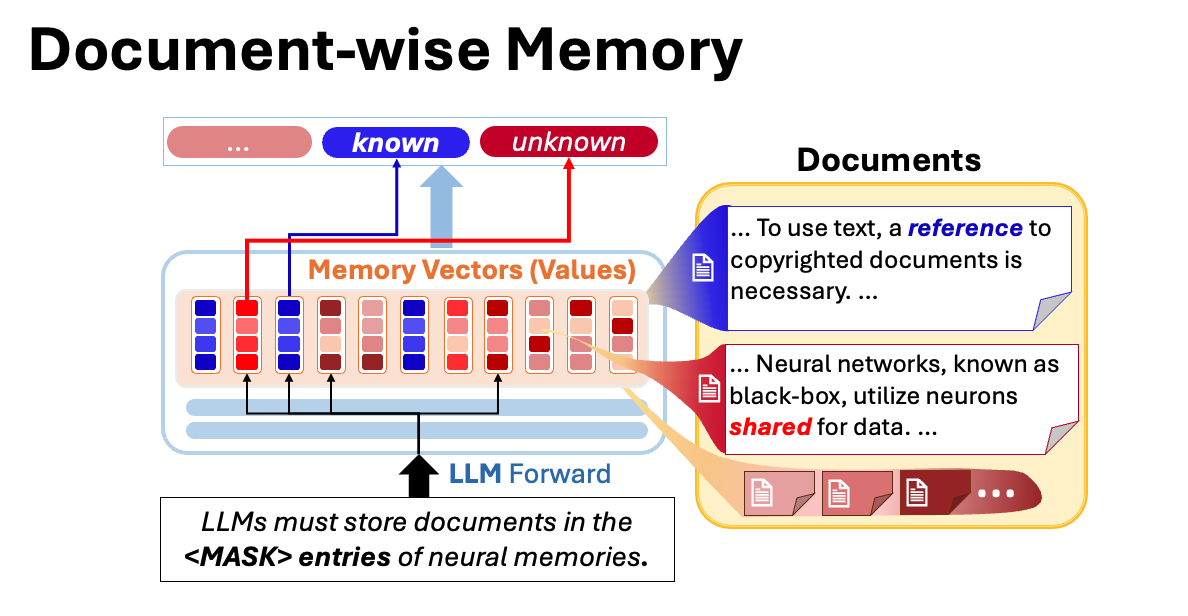
Figure: The model learns to select different memory entries per document, laying the foundation for document-specific memory design.
Result Highlight: Learning Dynamics of Memory Competition
We visualize how document memories evolve during training. As training progresses, documents increasingly specialize their memory entries, competing for distinct slots—leading to better separation and less contamination.
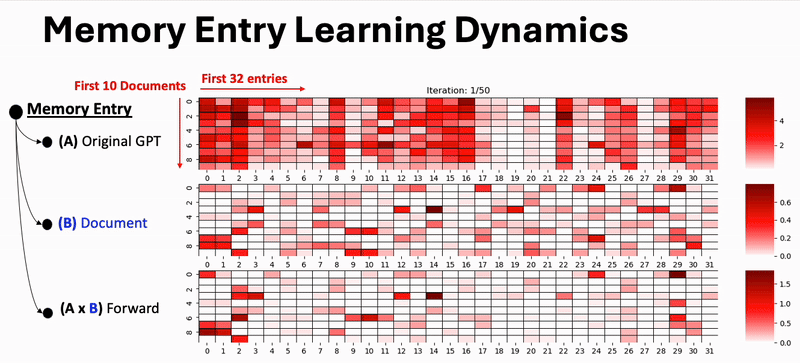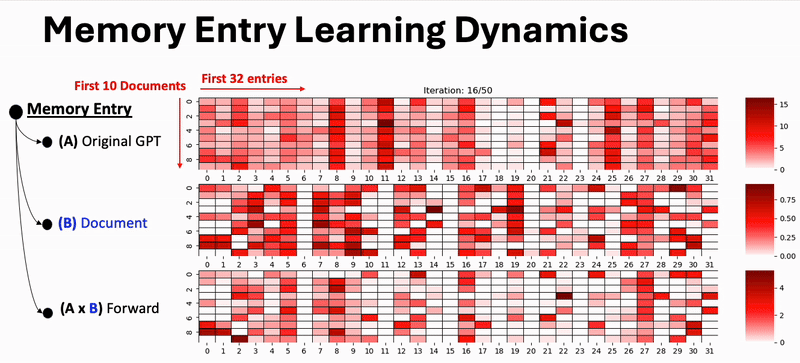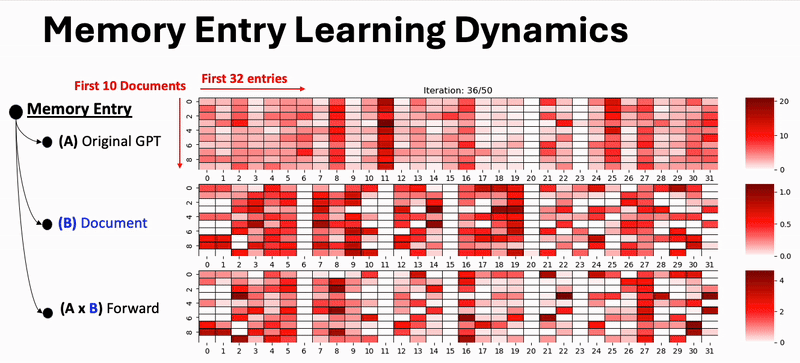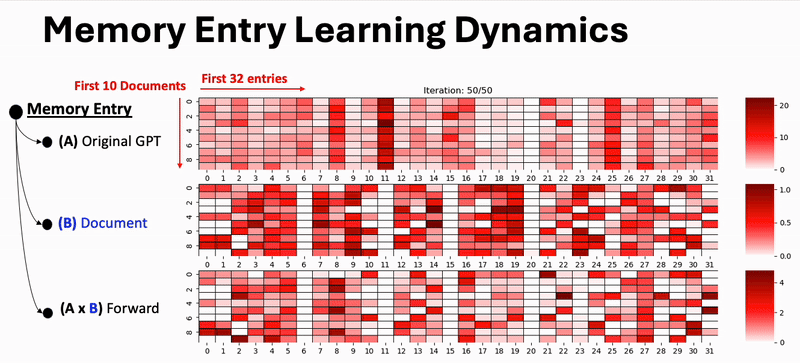
Figure: Competitive learning dynamics promote distinct memory entries across documents over training steps.
Analysis Highlights
Key-Value Memory Selection Architecture
This figure illustrates how document representations modulate memory selection. A key vector derived from a document representation is used to mask or activate specific memory entries in the MLP layers of a transformer, forming a soft selection mechanism.
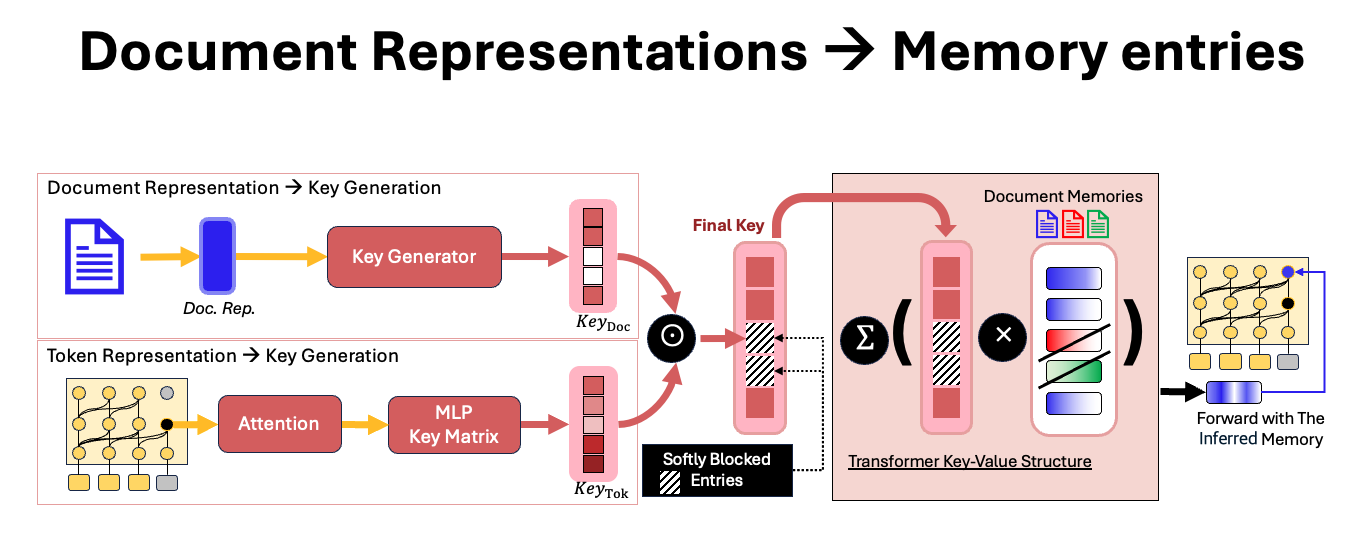
Figure: Document-based key vectors enable selective activation in the key-value memory structure of LLMs.
Document Guidance Loss
We introduce a training method based on guidance loss to align memory entries with document semantics. This loss increases the likelihood of the document text when using the correct document representation, while reducing it when using negative document representations.
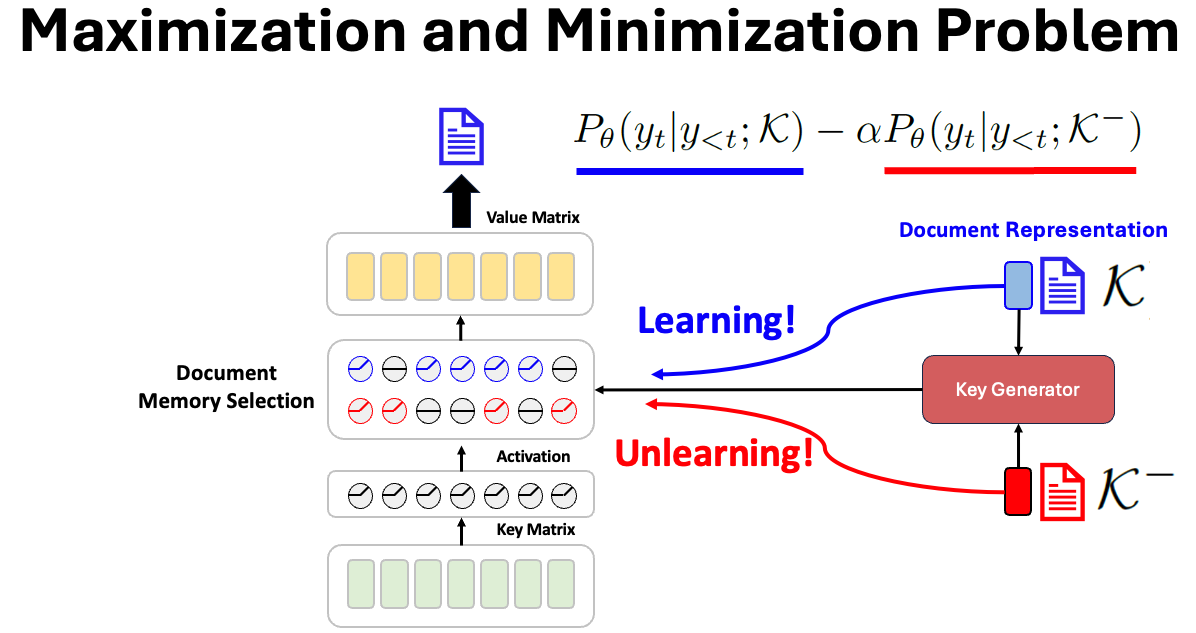
Figure: Document guidance loss entangles memory selection with the intended document while forgetting others.
Continuity in Document-to-Memory Mapping
We theorize and visualize how small changes in document representations should lead to smooth changes in memory selection. This Lipschitz continuity ensures stability and consistency across the memory selection manifold.
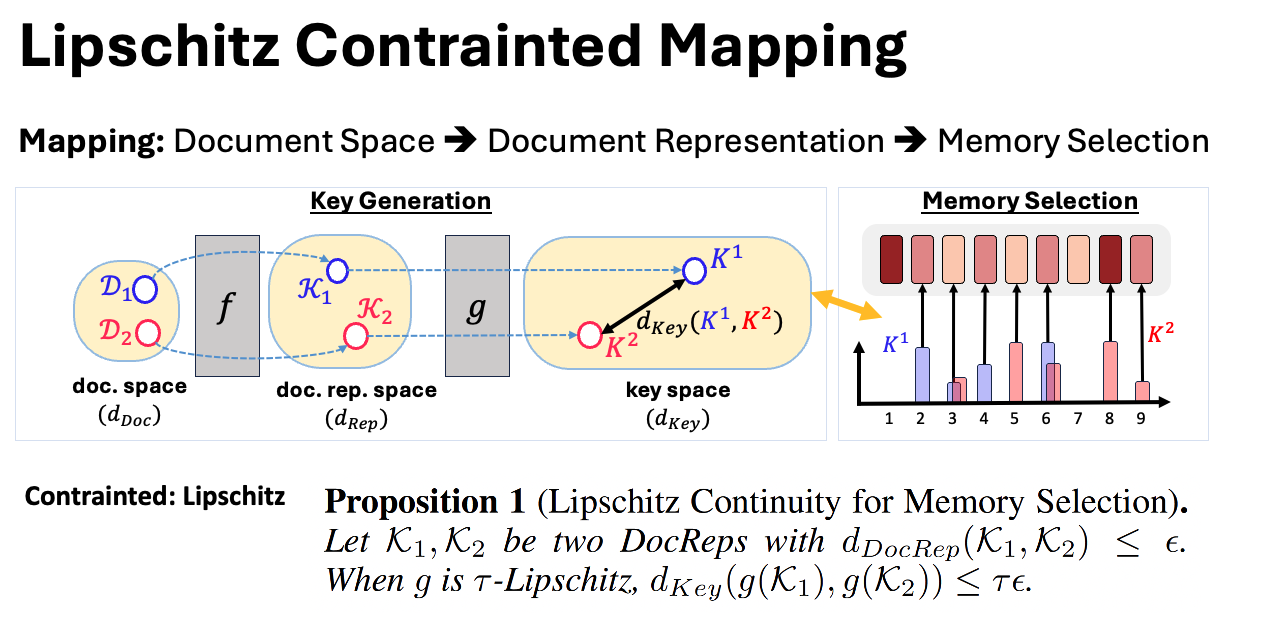
Figure: The continuity assumption preserves similarity between documents and their corresponding memory entries.
Improved Accuracy with Document-wise Memory
Experiments show that our method significantly improves the accuracy of content recall for the target document, compared to shared memory baselines. We evaluate this using ROUGE and IV-ROUGE scores on Wikitext-103.
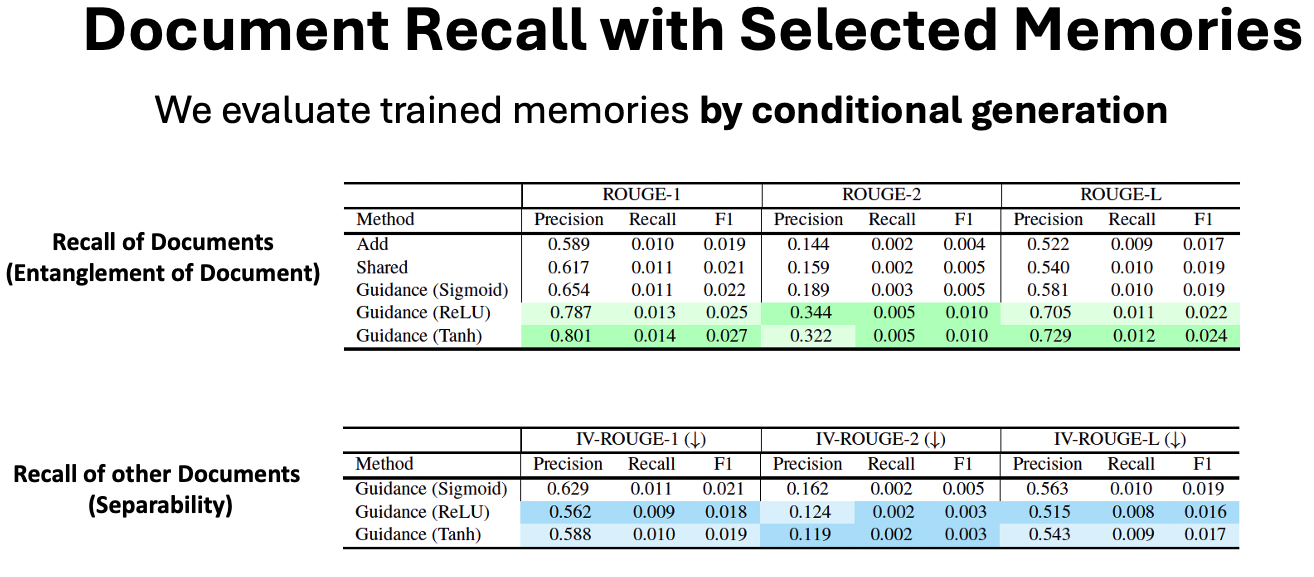
Figure: Document-wise memories improve generation quality by focusing on document-specific information.
Citation
@inproceedings{park2024guidance,
title = {Memorizing Documents with Guidance in Large Language Models},
author = {Park, Bumjin and Choi, Jaesik},
booktitle = {Proceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI)},
year = {2024},
}
Contact
If you have questions or collaboration ideas, feel free to reach out:
Email: bumjin@kaist.ac.kr